





Die Geschichte hinter Barracuda Active Threat Intelligence
Bei einer unserer Brainstorming-Sitzungen zum Thema Produktentwicklung wurde klar, dass das Erkennen und der Schutz vor neu aufkommenden digitalen Bedrohungen eine intensive Datenanalyse im großen Maßstab erforderte. Die Analyse der Risiken, denen unsere Kunden tagtäglich ausgesetzt sind, würde schnell und effizient vonstatten gehen müssen, wenn wir eine Chance gegen feindliche Aktivitäten haben wollten.
Bei der Bedarfsanalyse dieses Projekts wurde schnell klar, dass wir zum Schutz vor ausgefeilten Angriffen durch Bots eine Plattform erstellen mussten, die den Datenverkehr für Websitzungen analysieren und mit allen Sitzungsdaten korrelieren kann – und das für unseren gesamten Kundenstamm. Zudem lernten wir, dass die meisten Bereiche des Systems in Echtzeit, einige mit einer kurzen Verzögerung und andere wiederum mit einer viel längeren Analysephase arbeiten können.
Vor einigen Jahren führten wir Barracuda Advanced Threat Protection (BATP) ein, um die ganze Produktlinie von Barracuda vor Zero-Day-Angriffen zu schützen. Die Funktion – Dateianalyse zur Erkennung von Malware durch mehrere Engines in Begleitung von Sandboxing – wurde für die Produkte für Anwendungssicherheitsprodukte von Barracuda eingeführt, um Anwendungen wie Auftragsabwicklungssysteme mit Dateiuploads durch Dritte zu sichern. Dies war der erste Versuch, eine Cloud-basierte Ebene für fortgeschrittene Analysen zu verwenden, die nur schwierig in Web-Application-Firewall-(WAF-)Geräte zu integrieren gewesen wären.
Obwohl die BATP-Cloud-Ebene Millionen von Datei-Scans verarbeiten konnte, war es unmöglich, auf ihr große Mengen an Metainformationen abzuspeichern. Dies wurde jetzt aber nötig, damit Metadaten analysiert und zur Erkennung neuer Bedrohungen eingesetzt werden konnten. Das war der Beginn der neuesten Plattform: Active Threat Intelligence (ATI).
So funktioniert Active Threat Intelligence
Die ATI-Plattform ist unsere Antwort auf neuartige Bedrohungen. Die Plattform basiert auf einem riesigen Data Lake, der die Datenverarbeitung als Stream und Batch bewältigen kann. Active Threat Intelligence verarbeitet Millionen von Ereignissen pro Minute aus allen Ländern und liefert Informationen, die zur Erkennung von Bots und clientseitigen Angriffen verwendet werden, sowie Informationen zum Schutz vor diesen Bedrohungsvektoren. Wir haben bei dieser Technologie auf eine offene Architektur gesetzt, damit wir eine rasche Weiterentwicklung gewährleisten und auch die neuesten Bedrohungen eliminieren können.
Heute erhält die Barracuda ATI-Plattform Daten von den Security-Engines in der Barracuda-Web-Application-Firewall, von WAF-as-a-Service sowie von anderen Quellen. Sobald die Ereignisse eingehen, werden sie mittels Crowdsourcing-Bedrohungsfeeds und anderen Datenbanken erweitert. Clients werden entweder als Menschen oder Bots identifiziert, indem die Ereignisse sowohl einzeln als auch als Teil einer Benutzersitzung detailliert analysiert werden.
Pipelines zur Datenanalyse stützen sich auf verschiedene Engines und Modelle des maschinellen Lernens, um die verschiedenen Aspekte des Traffics zu analysieren. Sie sprechen Empfehlungen aus, die zusammengeführt werden, damit schließlich ein Gesamturteil herausgegeben werden kann.
Wie Active Threat Intelligence zum Schutz Ihrer Anwendungen beiträgt
Active Threat Intelligence unterstützt alle Analysen, die für Advanced Bot Protection erforderlich sind. Die Plattform wird aber auch für unsere neuesten Angebote – Client-Side Protection und Automated Configuration Engine – verwendet.
ATI verfolgt alle externen Ressourcen, die von der App verwendet werden können, z. B. ein externes JavaScript oder ein Stylesheet. Wir nehmen externe Ressourcen unter die Lupe, damit wir die Bedrohungslandschaft kennen und uns vor Angriffen wie MageCart schützen können.
Da die gesammelten Metadaten sehr umfangreich sind, können wir daraus zusätzliche Informationen ableiten, um Administratoren mit Konfigurationsempfehlungen zu unterstützen. Diese basieren auf dem realen Datenverkehr der Apps.
Diese Plattform war entscheidend für die Entwicklung der Sicherheitsfunktionen der nächsten Generation für unsere Kunden. Wir nutzen diese skalierbare Plattform nach wie vor, um detaillierte Einblicke zu Themen wie Traffic-Mustern oder Anwendungsgebrauch zu gewinnen. In weiteren Blog-Beiträge informiert Sie unser Team über die Entwicklung von Barracuda Advanced Threat Intelligence.

Anshuman Singh ist Senior Director Product Management bei Barracuda. Hier können Sie ihn auf LinkedIn kontaktieren.
Die Entwicklung der Daten-Pipeline
Für die modernen datenintensiven Anwendungen ist die Daten-Pipeline der zentrale Pfeiler.Im ersten Beitrag dieser Serie werfen wir einen Blick auf die Geschichte der Daten-Pipeline und wie sich die damit verbundenen Technologien im Laufe der Zeit entwickelt haben. Nachfolgend erfahren Sie, wie einige dieser Systeme bei Barracuda zum Einsatz kommen und was bei der Evaluierung von Komponenten der Daten-Pipeline zu beachten ist. Desweiteren führen wir einige Beispiele neuartiger Anwendungen an, die Ihnen den Einstieg in die Entwicklung und die Bereitstellung dieser Technologien erleichtern.
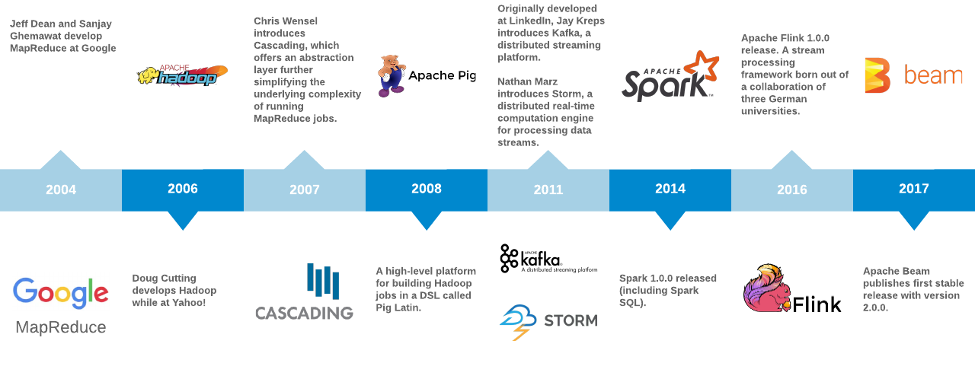
MapReduce
Im Jahr 2004 veröffentlichten Jeff Dean und Sanjay Ghemawat von Google MapReduce: Simplified Data Processing on Large Clusters. Sie beschrieben MapReduce wie folgt:
„[…] ein Programmiermodell samt Implementierung zur Verarbeitung und Erzeugung großer Datensätze.“ Benutzer legen sowohl eine Map-Funktion fest, die ein Schlüssel/Wert-Paar verarbeitet, um eine Reihe von Zwischen-Schlüssel/Wert-Paaren zu generieren, als auch eine Reduce-Funktion, die alle mit demselben Zwischenschlüssel verknüpften Zwischenwerte zusammenführt.“
Mit dem MapReduce-Modell konnten sie den parallelen Workload zur Generierung des Google Web-Index vereinfachen. Dieser Workload wurde einem Knoten-Cluster zugewiesen und bot eine Skalierbarkeit, die mit dem Web-Wachstum Schritt halten kann.
Ein wichtiger Aspekt von MapReduce ist, wie und wo Daten im Cluster gespeichert werden. Bei Google wurde dies als Google File System (GFS) bezeichnet. Eine Open-Source-Implementierung von GFS aus dem Apache-Nutch-Projekt wurde letztlich in eine Open-Source-Alternative zu MapReduce namens „Hadoop“ umgewandelt. Hadoop ist 2006 aus Yahoo! hervorgegangen. (Der Name Hadoop geht übrigens auf einen Spielzeugelefanten zurück, der dem Sohn von Doug Cutting gehörte.)
Apache Hadoop: Eine Open-Source-Implementierung von MapReduce
![]()
Hadoop fand auf Anhieb großen Zuspruch, deshalb führten Entwickler schon bald Abstraktionen ein, um Jobs auf einer höheren Ebene zu beschreiben. Während die Funktionen der Jobs (inputs, mapper, combiner und reducer) zuvor mit viel Aufwand beschrieben wurden (in der Regel in Java), konnten Benutzer nun dank Cascading-Software Daten-Pipelines mit gängigen Quellen, Senken und Operatoren erstellen. Mit der Hadoop-Erweiterung Pig beschrieben Entwickler Jobs auf einem noch höheren Niveau mithilfe von „Pig Latin“, einer völlig neuen Domain-spezifischen Sprache. Siehe Wortzahl in Hadoop, Cascading (2007) und Pig (2008) zum Vergleich.
Apache Spark: Eine einheitliche Analyse-Engine für die Verarbeitung großer Datenmengen
Im Jahr 2009 begann Matei Zaharia mit der Entwicklung von Spark im AMPLab der University of California in Berkeley. Sein Team veröffentlichte Spark: Cluster Computing with Working Sets im Jahr 2010, das eine Methode zur Wiederverwendung einer Arbeitsmenge von Daten über mehrere parallele Operationen hinweg beschreibt, und veröffentlichte die erste öffentliche Version im März desselben Jahres. Ein Folgepapier von 2012 mit dem Titel Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing wurde auf dem USENIX Symposium on Networked Systems Design and Implementation als Best Paper ausgezeichnet. In dieser Arbeit wird ein neuartiger Ansatz namens Resilient Distributed Datasets (RDDs) beschrieben, mit dem Programmierer In-Memory-Berechnungen nutzen können, um Größenordnung-Leistungssteigerungen für iterative Algorithmen wie PageRank oder maschinelles Lernen für dieselbe Art von Jobs zu erreichen, die auf Hadoop basieren.
Neben den Leistungsverbesserungen für iterative Algorithmen war die Fähigkeit, interaktive Abfragen durchzuführen, eine weitere bedeutende Innovation von Spark. Spark nutzt einen interaktiven Scala-Interpreter, der es Datenforschern ermöglicht, Schnittstellen zum Cluster einzurichten und viel unkomplizierter mit großen Datensätzen zu experimentieren, als das bisher möglich war. Zuvor musste ein Hadoop-Job erst kompiliert und eingereicht werden und anschließend wartete man auf die Ergebnisse.
Ein Problem blieb jedoch bestehen – die Eingabe in diese Hadoop- oder Spark-Jobs berücksichtigt nur Daten aus einer begrenzten Quelle (es werden keine neu eingehenden Daten während der Laufzeit des Jobs berücksichtigt). Der Job zielt auf eine Eingabequelle ab; bestimmt, wie der Job in parallelisierbare Datenblöcke oder Aufgaben zerlegt werden soll; führt die Aufgaben im gesamten Cluster gleichzeitig aus; und kombiniert schließlich die Ergebnisse und speichert die Ausgabe an irgendeinem Ort. Dieses Framework bewährte sich hervorragend bei der Generierung von PageRank-Indizes oder bei einer logistischen Regression. Für eine große Anzahl anderer Jobs, die es mit Daten aus einer unbegrenzten oder Streaming-Quelle zu tun hatten, wie z. B. Clickstream-Analysen oder Betrugsbekämpfungsmaßnahmen, war dies jedoch das falsche Framework.
Apache Kafka: Eine dezentrale Streaming-Plattform
2010 war das Engineering-Team von LinkedIn damit beschäftigt, das Fundament des beliebten sozialen Karrierenetzwerks neu zu gestalten [A Brief History of Kafka, LinkedIn's Messaging Platform]. Wie viele Websites wechselte LinkedIn von einer monolithischen Architektur zu einer Architektur mit vernetzten Microservices. Die Einführung einer neuen Architektur basierend auf einer universellen Pipeline, die auf einem dezentralen Commit-Log namens Kafka aufgebaut war, ermöglichte LinkedIn die Verarbeitung von Event-Streams nahezu in Echtzeit und in beachtlichem Umfang. LinkedIn-Chefentwickler Jay Kreps wählte den Namen „Kafka“, da es sich um ein System handelte, welches „für das Schreiben optimiert wurde“ und Kreps war ein Fan der Werke Franz Kafkas.
Die Hauptmotivation für die Einführung von Kafka bei LinkedIn lag darin, die bestehenden Microservices zu entkoppeln, damit sie sich freier und unabhängig voneinander entwickeln konnten. Zuvor war das Schema oder Protokoll, das für die Service-übergreifende Kommunikation verwendet wurde, die Koevolution der Services eingeschränkt. Das Infrastruktur-Team bei LinkedIn erkannte die Notwendigkeit einer erhöhten Flexibilität, um eine unabhängige Weiterentwicklung der Services zu gewährleisten. Sie entwarfen Kafka, um die Kommunikation zwischen den Services mithilfe einer asynchronen und nachrichtenbasierten Lösung zu erleichtern. Kafka musste sowohl langlebig (Nachrichten dauerhaft auf Festplatten speichern) als auch resistent gegen Netzwerk- und Knotenausfälle sein, nahezu Echtzeiteigenschaften bieten und horizontal skalieren um das Wachstum zu bewältigen. Kafka erfüllte diese Anforderungen, indem es ein dezentrales Log bereitstellte (siehe The Log: What every software engineer should know about real-time data's unifying abstraction).
Bis 2011 war Kafka Open-Source und wurde von vielen Unternehmen massiv eingesetzt. Im Vergleich zu vorherigen ähnlichen Message-Queue- oder Pub-Sub-Abstraktionen wie RabbitMQ und HornetQ führte Kafka die folgenden Neuerungen ein:
- Die Kafka-Topics (Queues) werden partitioniert, um sie über einen Cluster von Kafka-Knoten (die sogenannten Broker) zu skalieren.
- Kafka verwendet ZooKeeper für die Cluster-Koordination, Hochverfügbarkeit und Ausfallsicherung.
- Nachrichten werden für sehr lange Zeiträume auf der Festplatte gespeichert.
- Nachrichten werden der Reihe nach gelesen.
- Die Consumer behalten ihren eigenen Status bezüglich des Offsets der zuletzt gelesenen Nachricht bei.
Dank dieser Eigenschaften muss der Producer den Status hinsichtlich der Bestätigung jeder einzelnen Nachricht nicht beibehalten. Nachrichten konnten somit in hohem Maße in das Dateisystem gestreamt werden. Da die Consumer für das Beibehalten ihres eigenen Offsets im Topic zuständig sind, konnten Updates und Ausfälle effektiv von ihnen gehandhabt werden.
Apache Storm: Dezentrales Echtzeit-Berechnungssystem
In der Zwischenzeit, im Mai 2011 , unterzeichnete Nathan Marz einen Vertrag mit Twitter zur Übernahme seiner Firma BackType. Bei BackType handelte es sich um ein Unternehmen, das „Analytics-Produkte herstellte, mit denen Unternehmen ihren Einfluss auf soziale Medien sowohl historisch als auch in Echtzeit nachvollziehen konnten“ [History of Apache Storm and Lessons Learned]. Eines der Vorzeigeprodukte von BackType war ein Echtzeitverarbeitungssystem namens „Storm“. Storm führte eine Abstraktion mit dem Namen „Topology“ ein, mit der Stream-Operationen in ähnlicher Weise vereinfacht wurden, wie MapReduce es für die Stapelverarbeitung getan hatte. Storm wurde unter dem Beinamen „das Hadoop der Echtzeit“ bekannt und gelangte schnell an die Spitze von GitHub und Hacker News.
Apache Flink: Zustandsorientierte Berechnungen über Daten-Streams
Flink wurde im Mai 2011 erstmals der Öffentlichkeit vorgestellt. Flink geht auf ein Forschungsprojekt namens „Stratosphere“ zurück [http://stratosphere.eu/], das in Zusammenarbeit mit einer Handvoll deutscher Universitäten durchgeführt wurde. Stratosphere wurde mit dem Ziel entwickelt, „die Effizienz der massiv parallelen Datenverarbeitung auf Infrastructure-as-a-Service-Plattformen (IaaS-Plattformen) zu verbessern“ [http://www.hpcc.unical.it/hpc2012/pdfs/kao.pdf].
Ebenso wie Storm bietet Flink ein Programmiermodell zur Beschreibung von Datenflüssen (in der Flink-Sprache als „Jobs“ bezeichnet), die eine Reihe von Streams und Transformationen enthalten. Flink enthält eine Ausführung-Engine, um den Job effektiv zu parallelisieren und ihn in einem verwalteten Cluster zu planen. Eine einmalige Eigenschaft von Flink ist, dass das Programmiermodell sowohl begrenzte als auch unbegrenzte Datenquellen unterstützt. Das bedeutet, dass nur ein minimaler Unterschied in der Syntax zwischen einem Einmal-Ausführen-Job besteht, der Daten aus einer SQL-Datenbank bezieht (zuvor wäre dies wohl ein Batch-Job gewesen) und einem Andauernd-Ausführen-Job, der mit Streaming-Daten aus einem Kafka-Thema arbeitet. Flink trat im März 2014 in das Apache-Inkubationsprojekt ein und wurde im Dezember 2014 als Top-Level-Projekt akzeptiert.
Im Februar 2013 wurde die Alpha-Version von Spark Streaming mit Spark 0.7.0 veröffentlicht. Im September 2013 hat das LinkedIn-Team mit diesem Beitrag sein Stream-Processing-Framework „Samza“ veröffentlicht.
Im Mai 2014 wurde Spark 1.0.0 veröffentlicht und mit dieser Version wurde Spark SQL erstmalig eingeführt. Obwohl die aktuelle Spark-Version zu diesem Zeitpunkt nur eine Streaming-Funktion bot, die eine Datenquelle in „Micro-Batches“ aufteilte, wurden mit dieser Version die Voraussetzungen für die Ausführung von SQL-Abfragen als Streaming-Anwendungen geschaffen.
Apache Beam: Ein einheitliches Programmiermodell für Batch- und Streaming-Jobs
Im Jahr 2015 veröffentlichte ein Team von Google-Ingenieuren ein Papier mit dem Titel The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Eine Implementierung des Dataflow-Modells wurde 2014 auf der Google Cloud Platform kommerziell verfügbar gemacht. Sowohl das Core-SDK dieser Arbeit als auch mehrere I/O-Konnektoren und ein lokaler Runner wurden an Apache gespendet und im Juni 2016 in die erste Version von Apache Beam umgemünzt.
Einer der Schwerpunkte des Dataflow-Modells (und von Apache Beam) basiert darauf, dass die Darstellung der Pipeline unabhängig von der Wahl der Ausführungs-Engine abstrahiert wird. Zum Zeitpunkt des Schreibens kann Beam denselben Pipeline-Code erstellen, um Flink, Spark, Samza, GearPump, Google Cloud Dataflow und Apex anzusprechen. Infolgedessen haben Benutzer die Möglichkeit, die Ausführungs-Engine zu einem späteren Zeitpunkt weiter zu entwickeln, ohne die Implementierung des Jobs abzuändern. Zum Testen und Entwickeln in der lokalen Umgebung steht außerdem eine „Direct Runner“-Ausführungs-Engine zur Verfügung.
2016 führte das Flink-Team Flink SQL ein. Kafka SQL wurde im August 2017 angekündigt, und im Mai 2019 lieferte eine Gruppe von Ingenieuren von Apache Beam, Apache Calcite und Apache Flink "One SQL to Rule Them All: An Efficient and Syntactically Idiomatic Approach to Management of Streams and Tables " für ein einheitliches Streaming-SQL.
Ein Blick in die Zukunft
Die Tools, die den Softwarearchitekten für das Design der Daten-Pipeline zur Verfügung stehen, entwickeln sich mit zunehmender Geschwindigkeit weiter. Wir sehen, dass Workflow-Engines wie Airflow und Prefect Systeme wie Dask integrieren, um es Benutzern zu ermöglichen, massive Machine Learning-Workloads für den Cluster zu parallelisieren und zu planen. Aufstrebende Konkurrenten wie Apache Pulsar und Pravega konkurrieren mit Kafka, um die Speicherabstraktion des Streams zu übernehmen. Wir sehen auch Projekte wie Dagster, Kafka Connect und Siddhi , die bestehende Komponenten integrieren und neuartige Ansätze zur Visualisierung und Gestaltung der Datenpipeline liefern. Die rasante Weiterentwicklung der Technologien in diesen Bereichen macht die Entwicklung datenintensiver Anwendungen gerade jetzt besonders spannend.
Wenn Sie Interesse daran haben, mit derartigen Technologien zu arbeiten, sollten Sie sich mit uns in Verbindung zu setzten. Wir stellen Mitarbeitende für mehrere technische Positionen und an mehreren Standorten ein.

Robert Boyd ist Principal Software Engineer bei Barracuda Networks. Sein derzeitiger Fokus liegt auf dem skalierten sicheren Speichern und Durchsuchen von E-Mails.
Die Favoriten der Leser 2021
Wenn sich das Jahr allmählich dem Ende zuneigt, ist das immer eine gute Gelegenheit, unsere Lieblingsinhalte noch einmal gebührend ins Rampenlicht zu rücken. Dies sind die beliebtesten Barracuda-Blogbeiträge des Jahres 2020. Viel Spaß beim Lesen!
Ransomware und Datenlecks
- Wie Hacker Phishing bei Ransomware-Angriffen einsetzen
- Die größten Bedenken von Organisationen im Gesundheitswesen bezüglich Office 365 Backup
- 3 wichtige Maßnahmen zum Schutz vor Ransomware
- Cyberangriff von Colonial Pipeline offenbart die wirtschaftlichen Auswirkungen von Ransomware
Forschung
- E-Mail-Bedrohungen: URL-Phishing
- Threat Spotlight: Ransomware-Trends
- Threat Spotlight: Köder-Angriffe
Sonderberichte
- Network Security 2021 - Ein Überblick
- Application Security 2021 - Ein Überblick
- Cloud-Netzwerke – Transformation in Lichtgeschwindigkeit
- Einstieg in Office 365 Backup
- Einblicke in die wachsende Zahl automatisierter Angriffe
Below the Surface
- Below the Surface: Warum Sie eine Cloud-native Backup-Strategie brauchen
- Below the Surface: Förderung von Frauen in der Technik
- Below the Surface: Secure Access Service Edge mit Sinan Eren
Barracuda
- Barracuda wurde 2021 zum Visionär im Gartner® Magic Quadrant
 für Network Firewalls ernannt
für Network Firewalls ernannt - Barracuda wird von Comparably für die beste Unternehmenskultur ausgezeichnet
- 3 spannende Produktinnovationen auf der Secured.21 angekündigt.
- Hinter den Kulissen der Barracuda-Microsoft-Zusammenarbeit bei Cloud-to-Cloud-Backup
- Barracuda mit Eintrag in die „Security 100“-Liste 2021 von CRN gewürdigt
- Barracuda gewinnt den besten Kundenservice bei den SC Awards 2021
Altbewährte Themen
Manche Fragen verlieren nie an Aktualität. Warum kann ich z. B. meine private E-Mail-Adresse nicht auch für die Arbeit nutzen? Was soll das bedeuten, dass dieser Spam-Inhalt gar kein Spam ist? Deshalb finden die unten stehenden Beiträge immer wieder Einzug in die Kategorie „Leser-Favoriten“.
- Die geschäftlichen Risiken durch die Nutzung persönlicher E-Mail-Konten
- Ham und Spam: Wo liegt der Unterschied?
- Bedrohungsvektoren – was ist das und warum sollte man darüber Bescheid wissen?
Ausblick auf 2022
Im kommenden Jahr erwarten Sie weitere großartige Inhalte von unserem Expertenteam, unter anderem von Olesia, Tushar, Anastasia, Jonathan, Fleming und vielen mehr. Wir veröffentlichen unsere Beiträge mehrmals wöchentlich. Wenn Sie gerne über aktuelle Inhalte benachrichtigt werden möchten, abonnieren Sie einfach unseren Blog und wir senden Ihnen regelmäßig eine Zusammenfassung der neuesten Artikel per E-Mail. Alle paar Wochen erscheinen neue Folgen von Below the Surface. Sie können sich die archivierten Folgen auf unserer Website ansehen.
Das Barracuda-Team wünscht Ihnen ein frohes neues Jahr.

Christine Barry ist Senior Chief Blogger und Social Media Manager bei Barracuda. Bevor sie zu Barracuda kam, war Christine über 15 Jahre lang als Außendiensttechnikerin und Projektmanagerin für K12- und KMU-Kunden tätig. Sie hat mehrere Zugangsdaten für Technologie und Projektmanagement, einen Bachelor of Arts und einen Master of Business Administration. Sie ist Absolventin der University of Michigan.
Vernetzen Sie sich hier auf LinkedIn mit Christine.
Hochgradig skalierbare Ereignisprotokollierung auf AWS
Die meisten Anwendungen generieren Konfigurations- und Zugriffsereignisse. Administratoren müssen Aufschluss über diese Ereignisse erhalten können. Der Barracuda Email Security Service bietet Transparenz und Aufschluss zu vielen solchen Ereignissen, um Administratoren die Feinabstimmung sowie das Verständnis des Systems zu erleichtern. So können sie z. B. erfahren, wer sich wann bei einem Konto angemeldet hat – oder wer die Konfiguration einer bestimmten Richtlinie hinzugefügt, geändert oder gelöscht hat.
Bei der Erstellung eines solchen dezentralen und durchsuchbaren Systems kommen viele Fragen auf, z. B.:
- Wie soll man alle diese Protokolle von all diesen Anwendungen, Services und Geräten aus an einem zentralen Ort aufzeichnen?
- Welches Standardformat sollen die Protokolldateien aufweisen?
- Wie lange sollen diese Protokolle aufbewahrt werden?
- Wie soll man Ereignisse von verschiedenen Anwendungen zueinander in Beziehung setzen?
- Wie kann man einen einfachen, raschen Suchmechanismus über eine Benutzeroberfläche für den Administrator zur Verfügung stellen?
- Wie kann man diese Protokolle über ein API verfügbar machen?
Wenn man an verteilte Suchmaschinen denkt, fällt einem als Erstes Elasticsearch ein. Sie ist hochgradig skalierbar, ermöglicht eine Suche nahezu in Echtzeit und ist in AWS als vollständiger Managed Service verfügbar. Es begann also alles mit dem Gedanken, diese Ereignisprotokolle in Elasticsearch und all den verschiedenen Anwendungen zu speichern, die Protokolle über Kinesis Data Firehose an Elasticsearch senden.
An dieser Architektur beteiligte Komponenten
- Kinesis Agent – Amazon Kinesis Agent ist eine eigenständige Java-Softwareanwendung, die eine einfache Möglichkeit bietet, Daten zu sammeln und an Kinesis Data Firehose zu senden. Der Agent überwacht kontinuierlich Ereignisprotokolldateien auf den EC2-Linux-Instanzen und sendet sie an den konfigurierten Kinesis Data Firehose-Auslieferungsstream. Der Agent ist für Dateirotation, Checkpointing und erneutes Versuchen nach Fehlschlägen verantwortlich. Er stellt alle Daten auf zuverlässige, schnelle und unkomplizierte Art und Weise bereit. Hinweis: Wenn es sich bei der Anwendung, die Daten in Kinesis Firehose schreiben soll, um einen Fargate-Container handelt, benötigen Sie einen Fluentd-Container. Dieser Artikel konzentriert sich jedoch auf Anwendungen, die auf Amazon EC2-Instances ausgeführt werden.
- Kinesis Data Firehose – Die Direct-Put-Methode von Amazon Kinesis Data Firehose kann die Daten im JSON-Format in Elasticsearch schreiben. So werden keine Daten im Stream gespeichert.
- S3 – Ein S3-Bucket kann verwendet werden, um entweder alle Datensätze oder diejenigen Datensätze, die nicht an Elasticsearch übermittelt werden können, zu sichern. Lifecycle-Richtlinien können auch für eine automatische Archivierung von Protokollen konfiguriert werden.
- Elasticsearch – Elasticsearch wird von Amazon gehostet. Es kann der Zugriff auf Kibana aktiviert werden, um die Protokolle zu Debugging-Zwecken abzufragen und zu durchsuchen.
- Curator – AWS empfiehlt die Verwendung von Lambda und Curator zur Verwaltung der Indizes und Snapshots des Elasticsearch-Clusters. AWS hat weitere Details und Beispielimplementierung, die Sie hier finden können.
- REST API-Schnittstelle – Sie können eine API als Abstraktion für Elasticsearch erstellen, die sich gut in die Benutzeroberfläche integriert. API-gestützte Microservice-Architekturen sind nachweislich in vielerlei Hinsicht die besten, z. B. in Bezug auf Sicherheit, Compliance und Integration mit anderen Services.

Skalierung
- Kinesis Data Firehose: Standardmäßig können Firehose-Lieferströme auf bis zu 1.000 Datensätze/s oder 1 MiB/s für den Osten der USA (Ohio) skaliert werden. Das ist eine weiche Grenze und sie kann auf bis zu 10.000 Datensätze/Sek. erhöht werden. Diese Skalierungen sind abhängig von der Region.
- Elasticsearch: Der Elasticsearch-Cluster lässt sich sowohl im Hinblick auf Speicherplatz als auch auf Rechenleistung auf AWS skalieren. Auch Versionsupgrades sind möglich. Amazon ES verwendet beim Aktualisieren von Domains einen Bereitstellungsprozess vom Typ „blau/grün“. Somit kann die Anzahl von Nodes in dem Cluster vorübergehend ansteigen, während Ihre Änderungen übernommen werden.
Vorteile dieser Architektur
- Die Pipeline-Architektur wird effektiv vollständig verwaltet und überzeugt mit einem sehr geringen Wartungsaufwand.
- Im Falle eines Fehlschlagens des Elasticsearch-Clusters kann Kinesis Firehose Datensätze bis zu 24 Stunden lang aufbewahren. Außerdem werden Datensätze, die nicht zugestellt werden können, ebenfalls in S3 gesichert.
Mit diesen verfügbaren Optionen ist die Wahrscheinlichkeit von Datenverlusten gering.
- Es ist eine detaillierte Zugangskontrolle für die Kibana- und Elasticsearch-API über IAM-Richtlinien möglich.
Nachteile
- Die Preisgestaltung muss sorgfältig durchdacht und überwacht werden. Die Kinesis Data Firehose kann mühelos umfangreiche Dateneinspeisungen bewältigen. Wenn ein „wild gewordener“ Service auf einmal große Datenmengen protokolliert, liefert Kinesis Data Firehose sie ohne zu Fragen aus. Dies kann zu hohen Kosten führen.
- Die Integration von Kinesis Data Firehose mit Elasticsearch wird nur für Nicht-VPC-Elasticsearch-Cluster unterstützt.
- Die Kinesis Data Firehose kann derzeit keine Protokolle für Elasticsearch-Cluster bereitstellen, die nicht von AWS gehostet werden. Wenn Sie Elasticsearch-Cluster selbst hosten möchten, funktioniert diese Option nicht.
Fazit
Wenn Sie nach einer Lösung suchen, die vollständig verwaltet ist und sich (meist) ohne Eingreifen skalieren lässt, wäre dies eine gute Option. Das automatische Backup auf S3 mit Lifecycle-Richtlinien löst auch ganz unkompliziert das Problem hinsichtlich der Aufbewahrung und Archivierung von Protokollen.

Sravanthi Gottipati ist Engineering Manager Email Security bei Barracuda Networks. Hier können Sie sich auf LinkedIn mit ihr vernetzen.
DJANGO-EB-SQS: Vereinfacht die Kommunikation von Django-Anwendungen mit AWS SQS
AWS-Dienste wie Amazon ECS, Amazon S3, Amazon Kinesis, Amazon SQS und Amazon RDS werden weltweit in großem Umfang genutzt. Hier bei Barracuda verwenden wir AWS Simple Queue Service (SQS), um das Messaging innerhalb und zwischen den Microservices zu verwalten, die wir mit dem Django Framework entwickelt haben.
AWS SQS ist ein Message-Queuing-Service, der „Nachrichten zwischen Softwarekomponenten in beliebigem Umfang senden, speichern und empfangen kann, ohne dass Nachrichten verloren gehen oder andere Services verfügbar sein müssen“. SQS wurde entwickelt, um Unternehmen bei der Entkopplung von Anwendungen und der Skalierung von Diensten zu unterstützen, und es war das perfekte Tool für unsere Arbeit mit Microservices. Für jeden neuen Django-basierten Microservice oder die Entkopplung eines bestehenden Services mit AWS SQS mussten wir jedoch unseren Code und unsere Logik für die Kommunikation mit AWS SQS duplizieren. Das führte zu einer Menge an wiederholtem Code und ermutigte unser Team, diese GitHub-Bibliothek zu erstellen: DJANGO-EB-SQS
Django-EB-SQS ist eine Python-Bibliothek, die Entwicklern helfen soll, AWS SQS schnell in vorhandene und/oder neue Django-basierte Anwendungen zu integrieren. Die Bibliothek übernimmt die folgenden Aufgaben:
- Serialisieren der Daten
- Hinzufügen von Verzögerungslogik
- Kontinuierliche Abfrage aus der Warteschlange
- Deserialisieren der Daten gemäß den AWS-SQS-Standards und/oder Verwendung von Bibliotheken von Drittanbietern für die Kommunikation mit AWS SQS.
Kurz gesagt, es abstrahiert die gesamte Komplexität, die mit der Kommunikation mit AWS SQS verbunden ist, und ermöglicht es den Entwicklern, sich nur auf die Kernanwendungslogik zu konzentrieren.
Die Bibliothek basiert auf dem Django ORM Framework und der boto3 Bibliothek.
Anwendung
Unser Team arbeitet an einer E-Mail-Schutzlösung, die künstliche Intelligenz zur Erkennung von Spear-Phishing- und anderen Social-Engineering-Angriffen einsetzt. Wir integrieren sie in das Office 365-Konto unserer Kunden und erhalten Benachrichtigungen, wenn neue E-Mails bei ihnen eingehen. Eine der Aufgaben besteht darin, festzustellen, ob die neue E-Mail frei von Fraud ist oder nicht. Wenn wir solche Benachrichtigungen erhalten, kommuniziert einer unserer Dienste (Abbildung 1: Dienst 1) mit Office 365 über die Graph API und erhält diese E-Mails. Zur weiteren Verarbeitung dieser E-Mails und um die E-Mails für andere Dienste verfügbar zu machen, werden diese E-Mails dann in die AWS-SQS-Warteschlange verschoben (Abbildung 1: queue_1).

Abbildung 1
Schauen wir uns einen einfachen Anwendungsfall an, wie wir die Bibliothek in unseren Lösungen verwenden. Einer unserer Dienste (Abbildung 1: Dienst 2) ist dafür zuständig, Headers und Merkmale aus einzelnen E-Mails zu extrahieren und sie anderen Diensten zur Nutzung zur Verfügung zu stellen.
Dienst 2 ist so konfiguriert, dass er queue_1 abhört, um die unformatierten E-Mail-Texte abzurufen.
Nehmen wir an, Dienst 2 führt die folgenden Aktionen aus:
# E-Mail-Nachrichten aus queue_1 konsumieren
…
# Header und Merkmale aus E-Mails extrahieren
…
# Aufgabe einreichen
process_message.delay(tenant_id=, email_id=, headers=, tenant_id=, feature_set=, ….)
Diese process_message-Methode wird nicht synchron aufgerufen, sondern als Aufgabe in die Warteschlange gestellt und ausgeführt, sobald einer der Worker sie aufgreift. Der Worker hier könnte von demselben Dienst oder von einem anderen Dienst sein. Der Aufrufer der Methode muss sich keine Sorgen um das zugrunde liegende Verhalten und die Ausführung der Aufgabe machen.
Sehen wir uns an, wie die process_message-Methode als Aufgabe definiert wird.
aus eb_sqs.decorators Aufgabe importieren
@task(queue_name='queue_2′, max_retries=3)
def process_message(tenant_id: int, email_id: str, headers: List[dict], feature_set: List[dict], …) :
versuchen Sie:
# Ausführen einiger Aktionen mit Header- und Feature-Sets
# kann bei Bedarf auch weitere Aufgaben in die Warteschlange stellen
außer(OperationalError, InterfaceError) als exc:
versuchen Sie:
process_message.retry()
außer MaxRetriesReachedException:
logger.error(‘MaxRetries reached for Service2:process_message ex: {exc}')
Wenn wir die Methode mit dem Task Decorator ausstatten, werden zusätzliche Daten wie die aufrufende Methode, die Zielmethode, ihre Argumente und einige zusätzliche Metadaten hinzugefügt, bevor die Nachricht serialisiert und in die AWS-SQS-Warteschlange gestellt wird. Wenn die Nachricht von einem der Worker aus der Warteschlange konsumiert wird, verfügt er über alle Informationen, die für die Ausführung der Aufgabe erforderlich sind: welche Methode aufzurufen ist, welche Parameter zu übergeben sind und so weiter.
Wir können die Aufgabe auch im Falle einer Ausnahme wiederholen. Um jedoch ein unendliches Kreislaufszenario zu vermeiden, können wir einen optionalen Parameter max_retries festlegen, bei dem wir die Verarbeitung beenden können, nachdem wir die maximale Anzahl von Wiederholungen erreicht haben. Wir können dann den Fehler protokollieren oder die Aufgabe zur weiteren Analyse an eine Dead-Letter-Warteschlange senden.
AWS SQS bietet die Möglichkeit, die Verarbeitung der Nachricht um bis zu 15 Minuten zu verzögern. Wir können unserer Aufgabe eine ähnliche Fähigkeit hinzufügen, indem wir den Verzögerungsparameter übergeben:
process_message.delay(email_id=, headers=, …., delay=300) # Verzögerung um 5 Min.
Das Ausführen der Aufgaben kann durch Ausführen des Django-Befehls process_queue erzielt werden. Dies unterstützt das Abhören einer oder mehrerer Warteschlangen, das unbegrenzte Lesen aus den Warteschlangen und das Ausführen der eingehenden Aufgaben:
python manage.py process_queue –queues
Wir haben gerade gesehen, wie diese Bibliothek die Kommunikation innerhalb des Dienstes oder zwischen Diensten über AWS-SQS-Warteschlangen vereinfacht.
Weitere Informationen zum Konfigurieren der Bibliothek mit Django-Einstellungen und zum Abhören mehrerer Warteschlangen, zum Einrichten der Entwicklung und zu vielen weiteren Funktionen finden Sie hier.
Beitragen
Wenn Sie zum Projekt beitragen möchten, konsultieren Sie Folgendes: DJANGO-EB-SQS

Rohan Patil ist Principal Software Engineer bei Barracuda Networks. Derzeit arbeitet er an Barracuda Sentinel, einem KI-basierten Schutz vor Phishing und Account Takeover. In den letzten fünf Jahren hat er sich mit dem Thema Cloud-Technologien befasst und in den letzten 10 Jahren in verschiedenen Funktionen rund um die Softwareentwicklung gearbeitet. Er hat einen Master-Abschluss in Informatik von der California State University und einen Bachelor-Abschluss in Informatik, den er in Mumbai, Indien erlangt hat.
Mit GraphQL robuste und flexible APIs schreiben
Das API-Design ist ein Bereich, in dem es zwischen den Entwicklern von Client-Anwendungen und den Backend-Entwicklern oft zu Konflikten kommt. REST-APIs ermöglichen uns seit mehr als zwei Jahrzehnten die Entwicklung zustandsloser Server und den strukturierten Zugriff auf Ressourcen, und sie dienen der Branche weiterhin, vor allem wegen ihrer Einfachheit und moderaten Lernkurve.
REST wurde um das Jahr 2000 herum entwickelt, als die Client-Anwendungen noch relativ einfach waren und das Entwicklungstempo noch nicht so hoch war wie heute.
Bei einem herkömmlichen REST-basierten Ansatz würde der Entwurf auf dem Konzept der Ressourcen basieren, die ein bestimmter Server verwaltet. Dann verlassen wir uns in der Regel auf HTTP-Verben wie GET, POST, PATCH, DELETE, um CRUD-Vorgänge für diese Ressourcen durchzuführen.
Seit den 2000er Jahren haben sich mehrere Dinge geändert:
- Die zunehmende Nutzung von Single-Page-Anwendungen und mobilen Anwendungen führte zu einem effizienten Laden von Daten.
- Viele Backend-Architekturen sind von monolithischen zu µservice-Architekturen übergegangen, um schnellere und effizientere Entwicklungszyklen zu ermöglichen.
- Für APIs wird eine Vielzahl von Clients und Verbrauchern benötigt. REST macht es schwierig, eine API zu erstellen, die mehrere Clients unterstützt, da es eine feste Datenstruktur zurückgeben würde.
- Unternehmen erwarten, Funktionen schneller auf den Markt bringen zu können. Wenn eine Änderung auf Clientseite vorgenommen werden muss, ist häufig eine serverseitige Anpassung mit REST erforderlich, was zu langsameren Entwicklungszyklen führt.
- Die erhöhte Aufmerksamkeit für die Benutzererfahrung führt oft zur Entwicklung von Ansichten/Widgets, die Daten von mehreren REST-API-Ressourcenservern benötigen, um sie zu rendern.
GraphQL als Alternative zu REST
GraphQL ist eine moderne Alternative zu REST, die darauf abzielt, mehrere Mängel zu beheben. Seine Architektur und Tools sind darauf ausgelegt, Lösungen für moderne Softwareentwicklungspraktiken anzubieten. Es ermöglicht Clients, genau anzugeben, welche Daten benötigt werden, und erlaubt das Abrufen von Daten aus mehreren Ressourcen in einer einzigen Anfrage. Es funktioniert eher wie RPC, mit benannten Abfragen und Mutationen anstelle von standardmäßigen HTTP-basierten obligatorischen Aktionen. So bleibt die Kontrolle dort, wo sie hingehört: Der Backend-API-Entwickler gibt vor, was möglich ist, und der Client/API-Verbraucher gibt vor, was erforderlich ist.
Hier ist eine Beispiel-GraphQL-Abfrage, die mir die Augen geöffnet hat, als ich zum ersten Mal darauf gestoßen bin. Angenommen, wir erstellen eine Microblogging-Website und müssen dann 50 aktuelle Posts abfragen.
query recentPosts(count: 50, offset: 0) {
id
title
tags
content
author {
id
name
profile {
email
interests
}
}
}
Die obige GraphQL-Abfrage zielt darauf ab, Folgendes anzufordern:
- Letzte 50 Beiträge
- ID, Titel, Tags und Inhalt für jeden Blogeintrag
- Autoreninformationen, die ID, Name und Profilinformationen enthalten.
Wenn wir dafür einen traditionellen REST-API-Ansatz verwenden müssen, müsste der Client 51 Anfragen stellen. Wenn Posts und Autoren als separate Ressourcen betrachtet werden, ist das eine Anfrage zum Abrufen von 50 aktuellen Posts und dann 50 Anfragen zum Abrufen von Autoreninformationen für jeden Post. Wenn Autoreninformationen in die Beitragsdetails aufgenommen werden können, kann dies auch eine Anfrage mit REST API sein. Aber in den meisten Fällen, wenn wir unsere Daten mit Hilfe von Best Practices für die Normalisierung von relationalen Datenbanken modellieren, würden wir die Autoreninformationen in einer separaten Tabelle verwalten, und das führt dazu, dass die Autoreninformationen eine separate REST API-Ressource sind.
Hier ist der coole Teil von GraphQL. Angenommen, wir haben in einer mobilen Ansicht keinen Platz auf dem Bildschirm, um sowohl den Beitragsinhalt als auch die Profilinformationen des Autors anzuzeigen. Diese Abfrage könnte jetzt lauten:
query recentPosts(count: 50, offset: 0) {
id
title
tags
author {
id
name
}
}
Der mobile Client gibt nun die gewünschten Informationen an und die GraphQL-API liefert genau die Daten, um die sie gebeten wurde – nicht mehr und nicht weniger. Wir mussten weder serverseitige Anpassungen vornehmen, noch musste unser clientseitiger Code wesentlich geändert werden, und der Netzwerkverkehr zwischen Client und Server ist optimal.
Hier ist anzumerken, dass wir mit GraphQL flexible APIs entwerfen können, die auf clientseitigen Anforderungen und nicht auf einer serverseitigen Ressourcenverwaltung basieren. Eine allgemeine Wahrnehmung ist, dass GraphQL nur für komplexe Architekturen sinnvoll ist, die mehrere Dutzend µservices umfassen. Dies ist bis zu einem gewissen Grad richtig, da GraphQL im Vergleich zu REST-API-Architekturen eine gewisse Lernkurve aufweist. Diese Lücke schließt sich jedoch mit erheblichen intellektuellen und finanziellen Investitionen der aufstrebenden anbieterneutralen Foundation.
Barracuda ist ein Early Adopter von GraphQL-Architekturen. Wenn dieser Blogpost Ihr Interesse geweckt hat, finden Sie auf dieser Seite in Zukunft weitere Blogbeiträge, in denen ich mich mit weiteren technischen Details und architektonischen Vorteilen befassen werde.

Vinay Patnana ist Engineering Manager, Email Security Service bei Barracuda. In dieser Funktion unterstützt er das Design und die Entwicklung von Skalierbarkeitsdiensten von Barracuda E-Mail-Lösungen.
Vinay hat einen Master in Informatik von der North Carolina State University und einen Bachelor of Engineering vom BIT Mesra, Indien. Er arbeitet seit mehreren Jahren bei Barracuda und verfügt über mehr als ein Jahrzehnt Erfahrung in der Arbeit mit verschiedenen Arten von technischen Stacks. Hier können Sie sich auf LinkedIn mit ihm vernetzen.
Hinweis: Dieser Blog-Artikel wurde ursprünglich auf dem Databricks Company Blog veröffentlicht.
74 % aller Unternehmen weltweit sind bereits einem Phishing-Angriff zum Opfer gefallen.Barracuda Networks ist ein weltweit führendes Unternehmen für Sicherheits-, Anwendungsbereitstellungs- und Datenschutzlösungen, das Kunden dabei unterstützt, Phishing-Angriffe in großem Umfang zu bekämpfen. Barracuda hat eine leistungsstarke KI-Engine entwickelt, die mithilfe von Verhaltensanalysen Angriffe erkennt und böswillige Akteure in Schach hält.
Der Umgang mit Phishing-E-Mails ist aufgrund der Raffinesse, mit der Angreifer heutzutage bösartige E-Mails erstellen, keineswegs einfach. Barracuda Networks nutzt maschinelles Lernen (ML), um bösartige Nachrichten zu bewerten und zu identifizieren sowie seine Kunden zu schützen. Durch den Einsatz von ML auf der Databricks Lakehouse-Plattform ist das Team von Barracuda in der Lage, viel schneller zu arbeiten, und blockiert nun täglich Zehntausende von bösartigen E-Mails, die Millionen von Postfächern Tausender Kunden erreichen.
Umfassender Schutz für E-Mail-Sicherheit
Das Barracuda-Team hat sich der Erkennung von Phishing-Angriffen und der Sicherheit seiner Kunden verschrieben. Erreicht wird dies durch die Arbeit auf der Grundlage von Microsoft Office 365 sowie die Analyse des E-Mail-Verkehrs auf mögliche Bedrohungen. Wenn ein Angriff erkannt wird, wird die entsprechende E-Mail sofort aus dem Postfach entfernt, bevor die Benutzer sie sehen können.
Impersonation Protection
Eines der wichtigsten Produkte, die Barracuda anbietet, ist Impersonation Protection. Identitätsmissbrauch tritt auf, wenn böswillige Akteure ihre Nachrichten so tarnen, dass sie den Eindruck erwecken, sie würden von einer offiziellen Quelle stammen, z. B. von einer bekannten Führungskraft oder einem bekannten Dienst. Angreifer können diese Art von Angriff nutzen, um auf vertrauliche Informationen zuzugreifen, was sowohl für Einzelpersonen als auch für Unternehmen ein erhebliches Risiko darstellt.
Der Fokus von Impersonation Protection liegt auf der Abwehr gezielter Phishing-Angriffe. Derartige Versuche werden im Gegensatz zu Spam-E-Mails nicht in großen Mengen gesendet. Um einen gezielten Angriff zu versenden, muss der Angreifer über persönliche Daten des Empfängers verfügen, um den Angriff anzupassen, z. B. über dessen Beruf oder Arbeitsbereich. Für die Erkennung und Abwehr von Phishing-Angriffen mit dem Ziel des Identitätsmissbrauchs musste das Team eine Reihe von Klassifizierungsmodellen erstellen und diese für unsere Benutzer in der Produktion einsetzen.
Herausforderungen des Feature Engineering
Um unsere KI-Modelle für die Erkennung von Phishing- und Identitätsmissbrauchsangriffen angemessen zu trainieren, musste Barracuda die richtigen Daten verwenden und diese mithilfe von Feature Engineering ergänzen. Zu den Daten gehörten E-Mail-Text, der ein Signal für einen Phishing-Angriff sein könnte, und statistische Daten, wie z. B. Details zum E-Mail-Absender. Wenn ein Benutzer beispielsweise eine Rechnungs-E-Mail von jemandem erhält, der in den letzten Monaten keine ähnliche E-Mail verschickt hat, könnte dies ein Hinweis auf einen Phishing-Angriff sein. Vor der Databricks-Integration war das Erstellen von Features schwieriger, da die gekennzeichneten Daten über mehrere Monate verteilt waren, insbesondere bei den statistischen Features. Darüber hinaus war es schwierig, den Überblick über die Features zu behalten, wenn unser Datensatz gewachsen ist.
Langsame Bereitstellung
Unser Team hielt den Code und das Modell getrennt und musste den Forschungscode für die Produktionsumgebung duplizieren, was Zeit und Energie kostete. Wir haben zunächst jede eingehende E-Mail den Vorverarbeitungscode durchlaufen lassen und dann die vorverarbeiteten E-Mails zum Inferencing an das Modell weitergeleitet.
Erfolg für Barracuda dank Databricks
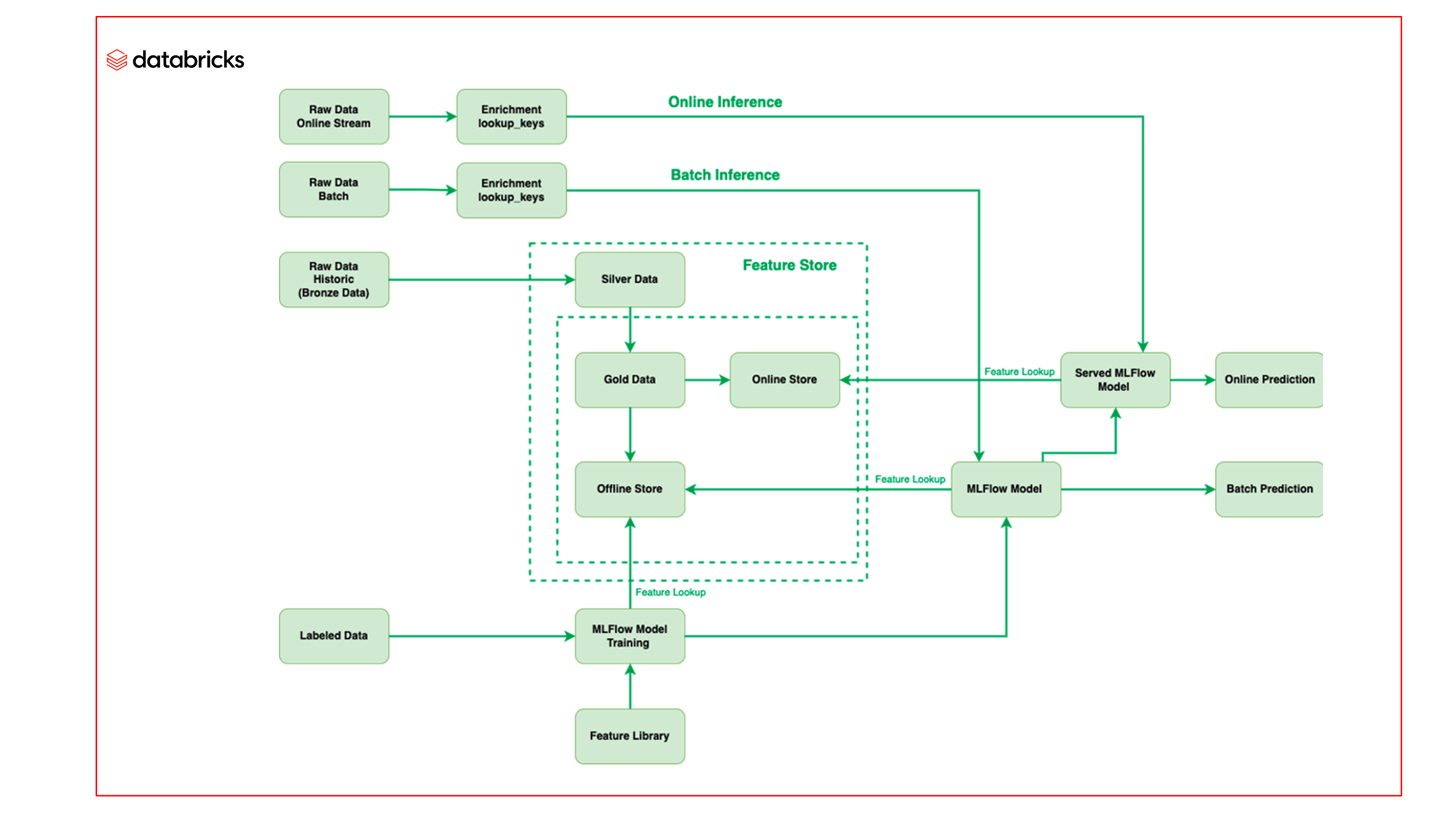
Das Team von Barracuda nutzte maschinelles Lernen auf der Databricks Lakehouse-Plattform – insbesondere den Databricks Feature Store und Managed MLflow –, um den ML-Prozess zu verbessern und in kürzerer Zeit Modelle mit besserer Qualität bereitzustellen.

Feature Store
Der Databricks Feature Store dient als zentrales Repository für alle vom Barracuda-Team verwendeten Features. Um statistische Features zu erstellen und zu pflegen, die ständig mit neuen Batches eingehender E-Mails aktualisiert werden, wurden im Feature Engineering gekennzeichnete Daten genutzt. Da der Feature Store auf Delta basiert, ist keine zusätzliche Verarbeitung erforderlich, um gekennzeichnete Daten in Features zu konvertieren, und die Features bleiben aktuell. Features werden in einem Offline-Repository aufbewahrt und Snapshots dieser Informationen werden dann online für die Verwendung im Online-Inferencing freigegeben. Darüber hinaus können diese Features durch die Integration von Databricks Feature Store und MLflow problemlos von den Modellen in MLflow aufgerufen werden, und das Modell kann das Feature zeitgleich mit dem Feature Retrieval abrufen, wenn die E-Mail zum Inferencing eingeht.
Schnellere maschinelle Lernvorgänge
Ein weiterer Vorteil ist die Verwaltung aller Modelle für maschinelles Lernen in MLflow. Mit MLflow kann das Team den gesamten Code innerhalb des Modells bewegen und ist daher in der Lage, die E-Mail zum Inferencing einfach durch das Modell laufen zu lassen, anstatt wie bisher den Code vorzuverarbeiten, was das Inferencing einfacher und schneller macht. Durch die Verwendung von MLflow ist das Team von Barracuda in der Lage, vollständig selbst paketierte Modelle zu erstellen. Diese Funktion reduziert die Zeit, die das Team für die Entwicklung von ML-Modellen aufwendet, erheblich.
Höhere Erkennungsrate
Mit Databricks verfügt das Team über mehr Zeit und mehr Berechnungen. Dadurch ist es möglich, regelmäßig eine neue Tabelle in Delta zu veröffentlichen, die Features täglich zu aktualisieren und anhand dieser zu erkennen, ob es sich bei einer eingehenden E-Mail um einen Angriff handelt oder nicht. Dies führt zu einer höheren Genauigkeit bei der Erkennung von Phishing-Angriffen und verbessert den Schutz und die Zufriedenheit der Kunden.
Auswirkungen
Mithilfe von Databricks schützt Barracuda Benutzer weltweit vor E-Mail-Angriffen. Jeden Tag hält das Team Zehntausende von bösartigen E-Mails davon ab, die Postfächer der Kunden zu erreichen. Das Team freut sich darauf, weiterhin neue Features von Databricks zu implementieren, um die Erfahrung unserer Kunden noch weiter zu verbessern.

{kind=link}
Mohamed Afifi Ibrahim ist ein Principal Machine Learning Engineer bei Barracuda.